日次でDB内のとあるテーブルのデータ全件をBigQueryに同期するバッチがあって
RDS for MySQLからデータをselectしていたが、先日Aurora MySQL(5.6.10)に移行した直後から急にバッチがこけはじめた。
原因調査
バッチは使用しているMySQLクライアントの設定値(3600秒)に従ってタイムアウトし落ちていた。
バッチの実行時間帯のCloud Watchメトリクスを確認してみると
AuroraのCPU使用率が30分間ほど平常値から外れて高くなっていた。
しかしバッチを実行しているEC2のネットワークインプットメトリックは特に変動がなく、Auroraからselectした結果を受け取れてなさそうなことも同時にわかった。
DBへの接続がタイムアウトするまでに1時間かかっているのに、selectによるCPU負荷が30分程度しか上昇していないので
クエリが何らかの理由で異常終了している可能性を疑い始める。
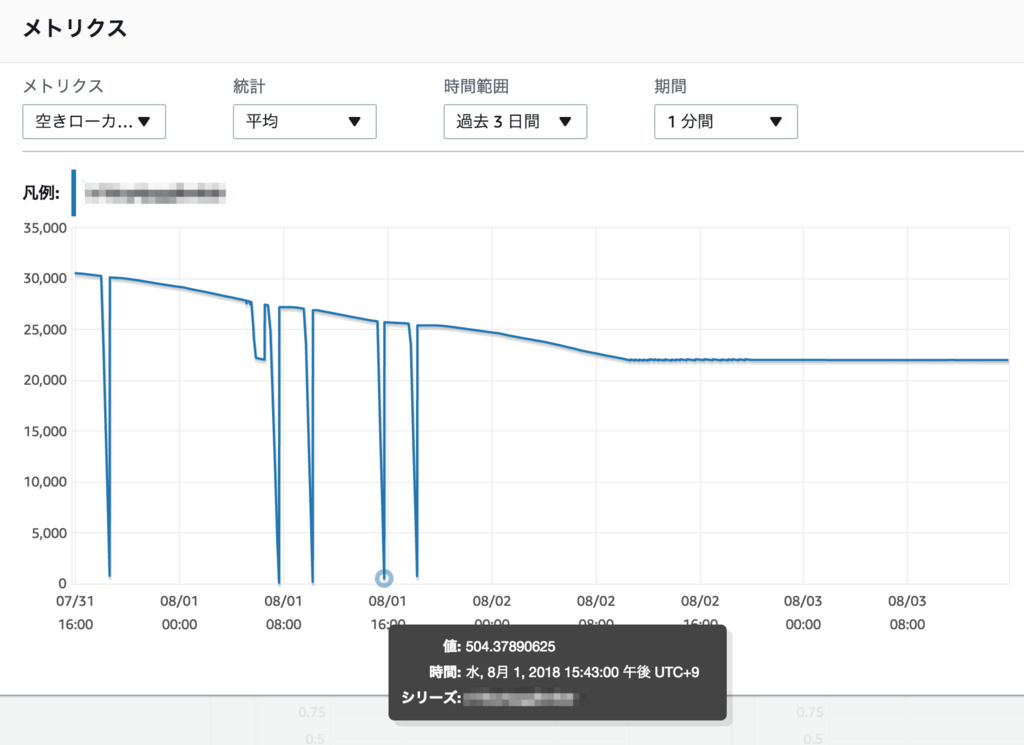
空きローカルストレージの急減少
引き続きメトリクスを眺めているとバッチ実行時間帯にAuroraの「空きローカルストレージ」が急減少していることも発見。
数十GBあるローカルストレージが、最も少ないタイミングで残り500MBまで減っているので枯渇している可能性を疑う。
ここまででクエリが正常に終了しているかもわからなかったので、確認用に同じバッチを再実行しshow processlistでクエリの実行状態を確認した。
バッチ実行初期は Sending dataというステータスだったクエリが、30分ほどで cleaned upというステータスに変わっていた。
参考:
テンポラリーテーブルの破損
クエリのステータスが変わったあたりのタイミングで以下のエラーログがAuroraのerror.logに出力されていた。 どうやらテンポラリーテーブルが壊れているっぽい。
2018-08-01 06:43:45 8918 [ERROR] /rdsdbbin/oscar/bin/mysqld: Incorrect key file for table '/rdsdbdata/tmp/#sql_22d6_0.MYI'; try to repair it 2018-08-01 06:43:45 8918 [ERROR] Got an error from unknown thread, /opt/brazil-pkg-cache/packages/OscarMysql/OscarMysql-1.0.201259.0/RHEL5_64/generic-flavor/src/oscar_mysql/mysql/storage/myisam/mi_write.c:223
これはCloudWatchで「空きローカルストレージ」が500MBを記録した45秒後に出力されているログ。 この時点でローカルストレージの枯渇により、テンポラリーテーブルが破損している可能性が非常に高いと思い始める。
MySQL 5.7.5以前は internal_tmp_disk_storage_engineのデフォルト設定がMyISAMで
テンポラリーテーブルがディスク容量を食いつぶすとクエリが途中終了されるようで、今回起こった「ローカルストレージの減少(枯渇)」x「クエリ結果がクライアント側に送信されない」現象と一致する。
参考:
- 日々の覚書: MySQL 5.7.6以降では暗黙のテンポラリーテーブルがあふれると死ぬ
- MySQL :: MySQL 5.7 Reference Manual :: 5.1.7 Server System Variables
インスタンスタイプを変えて再実行
ローカルストレージ枯渇が原因の可能性が高まったのでAuroraインスタンスのタイプを大きいものに変えて再実行。
information_schemaのテーブルサイズを参考にローカルストレージの容量に余裕のあるインスタンスを選択。
すると今度は無事にバッチが正常終了した。
やはりローカルストレージの枯渇が原因だった模様。
そもそもAuroraローカルストレージとは?
EC2でいうところのインスタンスストアに相当するものらしい。
テンポラリーテーブルなど一時的に利用するデータがここに書き込まれる。
EBSなどのストレージと違い簡単に増減はできずインスタンスタイプを大きなものに変更すると、このストレージも大きくなる。
参考:
- トラブルシューティング - Amazon Relational Database Service
- Zaim 500万ユーザに向けて〜Aurora 編〜
- ASCII.jp:そんな使い方あかん!やらかした事例満載のJAWS-UG大阪 (3/4)|JAWS-UG近畿・中国レポート
まとめ
- RDS for MySQLなどと違いAuroraにはローカルストレージというストレージが存在する
- ここの容量を変更するにはインスタンスタイプを変えるしかないため、発行するクエリやデータサイズを事前に計算しておく必要あり
- このストレージが枯渇すると5.7.5以前のエンジンではクエリが異常終了するのでCloudWatch Alarmなどで監視する必要がありそう